
Pytorch 3 Loss Activation DataLoader
Posted on 15/10/2021, in Italiano. Reading time: 33 minsIndice Globale degli argomenti tra i vari post:
1.1. Indice degli argomenti.
1.1. Introduzione e fonti.
1.1. Lingo - Gergo utilizzato.
1.2. Tensori in Pytorch.
2.1. Chainrule e Autograd.
2.2. Backpropagation.
3.1. Loss e optimizer.
3.2. Modelli di Pytorch.
3.3. Dataset e Dataloader.
3.4. Dataset Transforms.
3.5. Softmax e Cross-Entropy Loss.
3.6. Activation Function.
4.1. Feed Forward Neural Network.
5.1. Convolutional Neural Network.
5.2. Transfer Learning.
5.3. Tensorboard.
6.1. I/O Saving and Loading Models.
7.1. Recurrent Neural Networks.
7.2. RNN, GRU e LSTM.
8.1. Pytorch Lightning.
8.2. LR Scheduler.
9.1. Autoencoder.
LOSS e OPTIMIZER di PyTorch
Qqui vediamo qualche esempio di:
LOSSfunction (ovvero il criterion)Optimizer, ovvero le metodologie che vengono usate per fare l’update dei pesi per migliorare la loss (dato che devo minimizzare la loss sto facendo una ottimizzazione, o minimizzazione nel dettaglio!)
Questo codice e’ molto simile al precedente. La differenza e’ nell’optimizer, ovvero che strategia viene portata avanti per minimizzare le LOSS. In pratica ci sono varie funzioni che prendono come argomento il gradiente rispetto ad un tensore e minimizzano la funzione.
Passi:
- si disegna il modello
- si costruiscono la loss e l’optimizer
- si fa un loop di training
Consideriamo un grafo computazionale ancora del tipo linear regression.
optimizer.step() e’ il metodo che ci fa muovere tra i parametri secondo l’algoritmo di ottimizzazione.
import torch
import torch.nn as nn
# Linear regression
# f = w * x
# here : f = 2 * x
# 0) Training samples
X = torch.tensor([1, 2, 3, 4], dtype=torch.float32)
Y = torch.tensor([2, 4, 6, 8], dtype=torch.float32)
w = torch.tensor(0.0, dtype=torch.float32, requires_grad=True) # weights
def forward(x):
return w * x
print(f'Prediction before training: f(5) = {forward(5).item():.3f}')
# 2) Define loss and optimizer
learning_rate = 0.01 # questo viene passato come parmetro all'optimizer
n_iters = 100
loss = nn.MSELoss() # e' una funzione predefinita di Torch
optimizer = torch.optim.SGD([w], lr=learning_rate) # Optimizer ha come parameri di imput [w] (pesi) e lr=learning_rate
for epoch in range(n_iters): # TRAINING LOOP
y_predicted = forward(X) # FORWARD
l = loss(Y, y_predicted) # LOSS
l.backward() # Backward (e' un metodo sul tensore dato dalla loss)
optimizer.step() # Optimizer, uso il metodo .step()
optimizer.zero_grad() # azzera i gradienti usati per l'ottimizzatore
if epoch % 10 == 0:
print('epoch ', epoch+1, ': w = ', w, ' loss = ', l)
print(f'Prediction after training: f(5) = {forward(5).item():.3f}')
Prediction before training: f(5) = 0.000
epoch 1 : w = tensor(0.3000, requires_grad=True) loss = tensor(30., grad_fn=<MseLossBackward>)
epoch 11 : w = tensor(1.6653, requires_grad=True) loss = tensor(1.1628, grad_fn=<MseLossBackward>)
epoch 21 : w = tensor(1.9341, requires_grad=True) loss = tensor(0.0451, grad_fn=<MseLossBackward>)
epoch 31 : w = tensor(1.9870, requires_grad=True) loss = tensor(0.0017, grad_fn=<MseLossBackward>)
epoch 41 : w = tensor(1.9974, requires_grad=True) loss = tensor(6.7705e-05, grad_fn=<MseLossBackward>)
epoch 51 : w = tensor(1.9995, requires_grad=True) loss = tensor(2.6244e-06, grad_fn=<MseLossBackward>)
epoch 61 : w = tensor(1.9999, requires_grad=True) loss = tensor(1.0176e-07, grad_fn=<MseLossBackward>)
epoch 71 : w = tensor(2.0000, requires_grad=True) loss = tensor(3.9742e-09, grad_fn=<MseLossBackward>)
epoch 81 : w = tensor(2.0000, requires_grad=True) loss = tensor(1.4670e-10, grad_fn=<MseLossBackward>)
epoch 91 : w = tensor(2.0000, requires_grad=True) loss = tensor(5.0768e-12, grad_fn=<MseLossBackward>)
Prediction after training: f(5) = 10.000
Modelli di PyTorch
qui vediamo come usare i modelli preinstallati di pytorch.
- model = nn.Linear(input_size, output_size) modello lineare, ha 2 argomenti: i parametri in ingresso e in uscita.
- X = torch.tensor([[1], [2], [3], [4]]) occhio al formato [1] = prima riga, [2] =seconda riga, [3] = terza riga, [4]= quarta riga. X.shape = 4 righe, 1 colonna.
- ATTENTO: optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) all’ottimizzatore da’ in pasto un parametro, il learning rate.
import torch
import torch.nn as nn
# Linear regression
# f = w * x
# here : f = 2 * x
# 0) Training samples, watch the shape!
X = torch.tensor([[1], [2], [3], [4]], dtype=torch.float32)
Y = torch.tensor([[2], [4], [6], [8]], dtype=torch.float32)
n_samples, n_features = X.shape # 4 righe, 1 colonna. 4 osservazioni 1 sola FEATURE (predictor)
print(f'#samples: {n_samples}, #features: {n_features}')
print(X.shape)
#samples: 4, #features: 1
torch.Size([4, 1])
# 0) create a test sample
X_test = torch.tensor([5], dtype=torch.float32) # costruisco un nuovo punto per testare
# 1) Design Model, the model has to implement the forward pass!
# Here we can use a built-in model from PyTorch
input_size = n_features
output_size = n_features
# we can call this model with samples X
model = nn.Linear(input_size, output_size) # modello di PyTorch
'''
class LinearRegression(nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearRegression, self).__init__()
# define diferent layers
self.lin = nn.Linear(input_dim, output_dim)
def forward(self, x):
return self.lin(x)
model = LinearRegression(input_size, output_size)
'''
print(f'Prediction before training: f(5) = {model(X_test).item():.3f}')
learning_rate = 0.01 # learning rate
n_iters = 100 # numero iterazioni
loss = nn.MSELoss() # funzione loss
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# 3) Training loop
for epoch in range(n_iters):
# predict = forward pass with our model
y_predicted = model(X)
# loss
l = loss(Y, y_predicted)
# calculate gradients = backward pass
l.backward()
# update weights
optimizer.step()
# zero the gradients after updating
optimizer.zero_grad()
if epoch % 10 == 0:
[w, b] = model.parameters() # unpack parameters
print('epoch ', epoch+1, ': w = ', w[0][0].item(), ' loss = ', l)
print(f'Prediction after training: f(5) = {model(X_test).item():.3f}')
Dataset e DataLoader
Qui viene definito il dataloader. Supponi di avere un classificatore di immagini. In ingresso prende una immagine e in uscita mi dice a che classe appartiene (per esempio gatto-cane). Non posso fare il training su una sola immagine, altrimenti farei un overfit. Quello che normalmente si fa e’: passare dei batch (infornate di immagini), fare il training e poi fare il trainig su nuovi batch. In alcuni casi in modo incrementale, ovvero batch successivi includono quelli precedenti.
Secondo Python Engineer e’ anche vero il contrario. Se passp tutti i dati di training, allora fare delle gradient calculations (backpropagation) diventa computazionalemtne oneroso.
Osservazione di natura notazionale, di solito Loeber nelle istanze che crea, usa il medesimo
nome della funzione/classe di Torch, ma con tutte le lettere minuscole. Per esmpio, in PyTorch
esiste Dataset e lui chiama la sua istanza: dataset (minuscolo). Mi pare un’ottima
convenzione che aiuta a ricordare i nomi delle funzioni, metodi e classi.
- si fa un loop (esterno) su tutte le epoch
- per ogni epoch si fa un loop (interno) su tutti i batch
- l’ottimizzazione viene fatta solo sul batch
Lingo:
- epoch un passo forward e un backward di TUTTI i campioni del training.
- batch un sottoinsieme di elementi del training dataset
- batch_size numero di campioni di training in un forward/backward pass.
- numero di iterazioni numero di passi, ogni passo(forward/backward) usa “batch_size” campioni
Per esempio:
- 100 campioni
- batch_size=20
- 5 iterazioni formano 1 epoch
I DataLoader sono CLASSI, fanno la computazione del batch (la gestiscono). Vengono ereditati da “torch.utils.data import DataLoader.
- implementano un Dataset custom (voluto dall’utente)
- inherit Dataset
- implement __init__, __getitem__, e __len__
import torch
import torchvision
from torch.utils.data import Dataset, DataLoader
import numpy as np
import math
class WineDataset(Dataset): # Eredito dalla classe "Dataset" di torch.utils.data
def __init__(self): # metodo __init__, inizializza, leggi ecc
xy = np.loadtxt('./data/wine/wine.csv', delimiter=',', dtype=np.float32, skiprows=1)
self.n_samples = xy.shape[0] # definisce attributo n_samples = numero di righe
# Costruisci due attributi: sono i dati di training e le labels (come tensori)
self.x_data = torch.from_numpy(xy[:, 1:]) # size [n_samples, n_features]
self.y_data = torch.from_numpy(xy[:, [0]]) # size [n_samples, 1] (la colonna zero sono gli obiettivi)
# support indexing such that dataset[i] can be used to get i-th sample
def __getitem__(self, index): # questo mi fa scegliere i pezzi del dataset
return self.x_data[index], self.y_data[index]
# chiamando len(dataset) si ottiene la size
def __len__(self):
return self.n_samples
dataset = WineDataset() # carico il dataset
#first_data = dataset[0]
#features, labels = first_data
In questo dataset ci sono 3 categorie di vino e sono la prima colonna del dataset. Tutte le altre colonne sono le features. Quindi nella classe sopra ho diviso mettendo [0] per le label. A questo punto l’oggetto dataset contiene varie proprieta’.
Ora costruisco un dataloader, prendendo la classe che esiste gia’ in Torch.
Dato che ho gia’ importato l’oggetto DataLoader da torch.utils.data, basta che gli passo
i parametri corretti.
Dataset
In torchvision ci sono gia’ molti dataset disponibili che consentono di fare molti esperiemnti.
Le classi Dataset e Dataloader invece sono in torch.utils.data
- un Dataset e’
subscriptable(ovvero se si chiama mioDataset e faccio mioDataset[1], ottengo l’oggetto al secondo posto del dataset) - nel dataset (solitamente) ci sono sia i
datiche lelabel - non riesco a trasformare un dataset in una funzione iteratrice
DataLoader
- un DataLoader non e’
subscriptable, ma posso trasformarlo in un iteratore tramiteitere accedere quindi ai pezzi uno per volta (saranno i batch) - uso la funzione iter() per trasformare il dataloader in una funzione iteratrice (da mettere nei loop) (ho creato una nuova funzione che e’ l’iteratore del dataloader)
- a questo punto posso prendere i vari pezzi
- Attenzione se faccio
data=dataiter.next()ci possono essere dei problemi e il sistema puo’ non avere abbastanza memoria, per risolvere il problema si deve mettere:num_workers= 0(e non 2 come nell’esempio). https://stackoverflow.com/questions/60101168/pytorch-runtimeerror-dataloader-worker-pids-15332-exited-unexpectedly
Argomenti di un Dataloader:
dataset= mio_dataset()mio_datasete’ un oggetto ereditato dadataset(usa dataset come nome standard, in modo da ricordare)batch_size = 4(oppure crea una variabile batch_size)shuffle=True(fa shuffling, non chiaro in quali circostanze usare, la logica vuole che quando si costruiscono i train e validation sets si facciano dei sampling random. Per questo si fa lo shuffling all’interno del datasetnum_workers(occhio che se metto 4 come nel tutorial mi da errore: devo mettere 0)
batch_size = 4
num_workers = 0
dataloader = DataLoader(dataset=dataset, batch_size = batch_size, shuffle = True, num_workers = num_workers)
dataiter = iter(dataloader) # trasformato in una funzione iteratrice
data = dataiter.next() # prendo il prossimo oggetto (il primo)
#data = next(dataiter)
#features, labels = data
#print(features, labels)
A questo punto fa un training loop finto per provare a vedere come funge.
Attentoin enumerate non mette la funzione iteratrice ma ildataloader.- ho provato a fare iterare su data ma da’ errore: too many values to unpack (expected 2)
- occhio la cella sotto funge anche con dataiter solo se prima faccio girare la cella sopra.
#for i, j in enumerate(dataloader):
# print(i,j)
dataloader
<torch.utils.data.dataloader.DataLoader at 0x216799d3670>
#for i, j in enumerate(dataset):
# print(i,j)
id = iter(dataset)
id.next()
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-33-4dc6e5e585ab> in <module>
2 # print(i,j)
3 id = iter(dataset)
----> 4 id.next()
AttributeError: 'iterator' object has no attribute 'next'
num_epochs = 2
total_samples = len(dataset)
n_iterations = math.ceil(total_samples/batch_size) # ceil altrimenti arrotonda per difetto
#n_iterations
for epoch in range(num_epochs): # giro tra le epoche
for i, (inputs, labels) in enumerate(dataloader): # qui ha passato il dataloader
if (i+1)%5 == 0:
#print( f'epoch {epoch+1}/{num_epochs}, step {i+1}/{n_iterations}, inputs {inputs.shape}' )
pass # se non voglio stampare altrimenti decommenta sopra
# Idea mia, e se invece di usare un enumerate usassi data (che e' una funzione iteratrice?)
#j=0
#for epoch in range(num_epochs): # giro tra le epoche
# for inputs, labels in dataiter: # qui ha passato il data (iteratrice)
# j=j+1
# print(j)
# if (j+1)%5 == 0:
# print( f'epoch {epoch+1}/{num_epochs}, step {j+1}/{n_iterations}, inputs {inputs.shape}' )
# dataset pre-installati:
#torchvision.datasets.MNIST() # occhio che e' M N I S T
# fashion-mnist
# cifar
# coco
Dataset Transforms
In pratica si deve passare un argomento transform alla classe associata al dataset.
Documentazione sulle possibili trasformazioni: https://pytorch.org/docs/stable/torchvision/transforms.html
riassunto delle trasformazioni (UTILE, lo fa Python engineer):
Quando carichi un dataset da torchvision puoi usare l’argomento: download=True!
Traformazioni sulle Immagini:
- CenterCrop, Grayscale, Pad, RandomAffine, RandomCrop, RandomHorizontalFlip, RandomRotation, Resize, Scale
Sui Tensori:
- LinearTransformation, Normalize, RandomErasing
Conversion:
-ToPILImage: da tensore o ndarray (PILI = Pillow image)
-ToTensor: da numpy.ndarray o PILImage
Generic:
- lambda
Custom:
- Si puo’ scrivere una propria classe
Trasformazioni composte multiple:
-
composed = transforms.Compose( [Rescale(256] , RandomCrop(224)] )
- torchvision.transforms.ReScale(256) # occhio che qui ha messo S maiuscola
- torchvision.transforms.ToTensor()
Trasformazioni
Ora prendo la classe usata sopra per i dataset e aggiungo un argomento: transform,
che specifica quali trasformazioni posso applicare!
- va passato qualcosa al momento della creazione della classe dataset
- viene fatto un esempio con una
trasformazione custom, usando una classe - ho un problema, mi dice che, al contrario del codice del corso, WineDataset non ha l’attributo transform. in particolare succede se faccio: dataset = WineDataset(transform =ToTensor()) dataset[0] <- qui e’ il problema
import torch
import torchvision
from torch.utils.data import Dataset
import numpy as np
#dataset = torchvision.datasets.MNIST(root='./data', download= True, transform=torchvision.transforms.ToTensor())
class WineDataset(Dataset):
def __init__(self,transform=None): # posso anche non passare transform, di default = None
xy = np.loadtxt('./data/wine/wine.csv', delimiter=',', dtype=np.float32, skiprows=1)
self.n_samples = xy.shape[0]
self.x = xy[:, 1:]
self.y = xy[:,[0]] # NOTA che scrivo [0]
self.transform = transform # quando chiamo la trasformazione dall'istanza.
def __getitem__(self, index): # questo mi prende lo specifico dato alla posizione index
#return self.x[index], self.y[index] # non ritorna l'oggetto, ma voglio trasformare!
sample = self.x[index], self.y[index] # costruisco l'oggetto
if self.transform: # se e' presente
sample = self.tranform(sample)
return sample # lo metto qui in modo che ritorni qualcosa comunque
def __len__(self):
return n_samples
############## trasformazione custom ###############
############## abbiamo bisogno di un metodo chiamato __call__
class ToTensor:
def __call__(self, sample): ############## FONDAMENTALE ##########
inputs, targets = sample
return torch.from_numpy(inputs), torch.from_numpy(targets)
#dataset = WineDataset(transform =None)
#dataset = WineDataset(transform=ToTensor)
#dataset = WineDataset(transform = ToTensor())
#dataset[0]
#first_data = dataset[0] ################### NON FUNGE #################
#features, labels = first_data
#print(type(features), type(labels))
## posso fare trasoformazioni multiple:
class MulTransform:
def __init__(self, factor):
self.factor = factor
def __call__(self, sample):
inputs, targets = sample
inputs *= self.factor
return inputs, target
composed = torchvision.transforms.Compose([ToTensor(), MulTransform(2)])
dataset = WineDataset (transform = composed)
#first_data = dataset[0] ###################### NON FUNGE #####################
Softmax e Cross-Entropy Loss
Queste sono tra le funzioni piu’ comuni per “schiacciare i risultati” (un po’ come la logit(p) =ln(p/1-p) =ln(odds) )
Softmax:
\(\displaystyle S(y_i) = \frac{e^{y_i}}{\sum e^{y_i}}\)
I risultati vanno quindi tra 0 e 1.
A denominatore sembra una funzione di ripartizione (ma i valori non sono negativi).
Chiaramente $ \sum S(y_i) =1$ quindi le $S(y_i)$ possono essere interpretate come delle probabilita'.
Per questo vengono applicate come layer in uscita dopo l’ultimo strato in modo che ad ognuna delle classi sia associata una probabilita’.
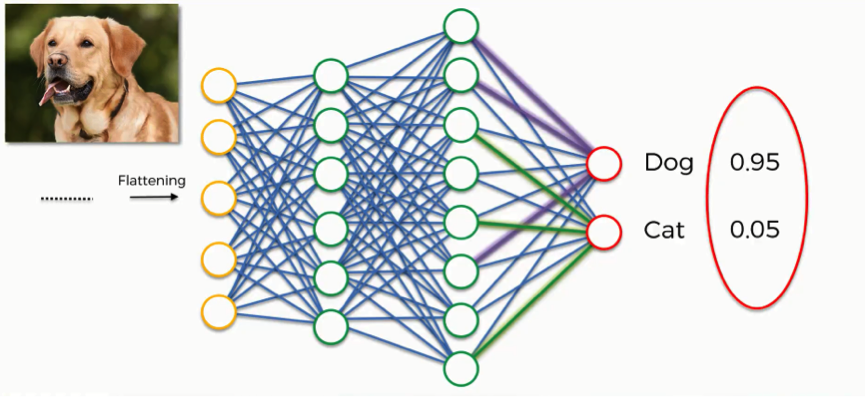
-
Se fossero solo 2 le classi come nella regressione logistica si userebbe la sigmoid function (che e’ la versione non generalizzata ma con solo 2 classi in pratica): \(Sigmoid(x) = \frac{1}{1+e^{-x}}\)
-
Come Loss si potrebbe usare la
nn.BCELoss()(binary cross entropy loss). In questo caso pero’ BISOGNA implementare la sigmoide dopo l’ultimo strato. -
La cross entropy di Pytorch implementa gia’ la softmax dall’ultimo strato, per questo bisogna evitare di applicare la softmax un’altra volta!
import numpy as np
import torch.nn as nn
import torch
import matplotlib.pyplot as plt
def softmax(x): # costruisco una softmax di un ARRAY x
return np.exp(x)/ np.sum( np.exp(x) , axis = 0) # ho tutti gli elementi
def sigmoid(x):
return 1./(1.+np.exp(-x))
x = np.array([2.,1.,0.1])
print(softmax(x))
########## qui uso una softmax gia' presente in Torch
x = torch.tensor([2.,1.0,0.1])
outputs = torch.softmax(x, dim=0) # devo specificare la dimensione dove giro
print(outputs)
x= [i-500 for i in range(1000)]
x = np.array(x)
x = x *0.01
exp = np.exp(x)
x =torch.from_numpy(x)
y = torch.softmax(x, dim=0 )
#y = sigmoid(x)
plt.plot(x,y)
plt.plot(x, sigmoid(x))
#x
[0.65900114 0.24243297 0.09856589]
tensor([0.6590, 0.2424, 0.0986])
[<matplotlib.lines.Line2D at 0x2165c85f910>]
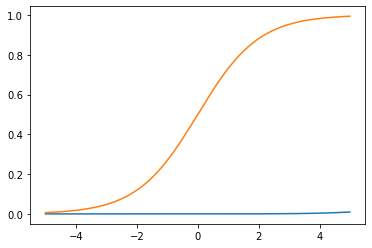
Cross-Entropy Loss
La Cross-Entropy Loss e’ una funzione di Loss, che viene spesso combinata alla soft-max.
Come la maggior parte delle funzioni di Loss trasforma i valori ottenuti (output) e le label in un singolo valore. Dato ci sono 2 vettori N-dimensionali:
- il vettore calcolato (a partire dall’input) $\hat{Y}= [0.7, 0.2, 0.1]$ Gli ingressi devono poter essere interpretabili come probabilita’, ergo devono essere nel range (0,1]. Questo e’ il motivo per cui gli si danno in pasto dei valori che sono gia’ stati convertiti con delle Softmax.
- e quello osservato $Y= [1,0,0]$ (One-Hot Encoded labels)
dubbio, ma cosi’ facendo non e’ manco piu’ una somma! tutte le $Y_i$ vengono azzerate tranne 1. E’ vero solo se faccio un oggetto per volta. Se faccio un batch di oggetti e quindi sommo i risultati (per ottenere la empirical loss), avro’ piu’ di un valore diverso da 0.
la Cross Entropy Loss viene definita come:
\(D(\hat{Y}, Y) = - \frac{1}{N} \sum Y_i \cdot log(\hat{Y}_i)\)
Nota che la Cross-Entropy loss restituisce valori [0,1].
Migliore la predizione, piu’ bassa e’ la Loss.
Domanda: come ottengo questa formula a partiere dall’entropia di Shannon?
Quindi e’ un’entropia di Shannon ma in cui da un lato inserisco i valori osservati e quelli ottenuti. Chiaramente serve che le Y e $\hat{Y}$ siano in un range [0,1] se voglio ottenere dei risultati simili all’entropia di Shannon.
Attenzione nel codice del video, Loeber non segue la definizione in quanto non divide per il numero di oggetti, non so perche’. Quindi i risultati che ottiene non sono nel range [0,1]
def cross_entropy(actual, predicted): # sono 2 array N-dim
loss = -(np.sum( actual * np.log(predicted) )) /len(actual)
return loss
y = np.array([1,0,0])
y_pred_good = np.array([0.7,0.1,0.1])
y_pred_bad = np.array([0.1,0.4,0.5])
l1 = cross_entropy(y, y_pred_good)
l2 = cross_entropy(y, y_pred_bad)
print(f'Loss1 : {l1:.4f}')
print(f'Loss2 : {l2:.4f}')
Loss1 : 0.1189
Loss2 : 0.7675
CrossEntropyLoss
la funzione nn.CrossEntropyLoss usa gia’:
nn.LogSoftMax -> nn.NLLLos (negative log likelihood loss)
Per questo NON le (a nn.LogSoftMax) si devono dare in pasto i vettori codificati tramite:
- One Hot encoding (NO)
- Softmax (NO)
La funzione di Loss in PyTorch consente di avere samples multipli.
Ovvero si ha una loss per il primo sample, una per il secondo sample, ecc in pratica viene un vettore di loss.
######## QUI usiamo la cross entropy embedded in Torch
Y = torch.tensor([0]) # questa e' la classe corretta e' UN Solo valore
#qui sotto la dimensione e' n_samples x n_classes = 1 x 3 (in questo caso)
## e' un ARRAY di ARRAY
Y_pred_good = torch.tensor( [ [ 2.0, 1.0, 0.1] ] ) # e' buona perche' la classe 0 ha il valore maggiore
Y_pred_bad = torch.tensor( [ [ 0.5, 2.0, 0.3] ] ) # e' cattiva perche' il valore maggiore e' per la classe 1
loss = nn.CrossEntropyLoss() # istanzio la funzione
print(loss (Y_pred_good, Y ).item())
print(loss (Y_pred_bad , Y ).item())
### per ottenere le predizioni:
_, pred1 = torch.max (Y_pred_good, 1) # il secondo ingresso e' la dimensione dove gira?
_, pred2 = torch.max (Y_pred_bad, 1)
print(pred1)
print(pred2)
############## sample multipli ###########################
Y = torch.tensor([2,0,1]) # vettore 3 (n_samples)
# vettore n_labels x n_samples
Y_pred_good = torch.tensor( [ [ 0.1, 1.0, 2.1] ,
[ 2.0, 1.0, 0.1] ,
[ 0.1, 3.0, 0.1] ] )
Y_pred_bad = torch.tensor( [ [ 2.1, 1.0, 0.1] ,
[ 0.1, 1.0, 2.1] ,
[ 0.1, 3.0, 0.1] ] )
print(loss (Y_pred_good, Y ).item())
print(loss (Y_pred_bad , Y ).item())
_, pred1 = torch.max (Y_pred_good, 1) # il secondo ingresso e' la dimensione dove gira?
_, pred2 = torch.max (Y_pred_bad, 1)
print(pred1)
print(pred2)
0.4170299470424652
1.840616226196289
tensor([0])
tensor([1])
0.3018244206905365
1.6241613626480103
tensor([2, 0, 1])
tensor([0, 2, 1])
Esempio Applicazione di Softmax
- un solo hidden layer con
hidden_sizenodi input_sizee’ per esempio il num di punti dell’immaginenum_classese’ il numero di possibili classi in uscita (output_size)
import torch
import numpy as np
import torch.nn as nn
class NeuralNet2(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(NeuralNet2, self).__init__() # questo serve per ereditare il costruttore?
self.linear1 = nn.Linear(input_size, hidden_size) #
self.relu = nn.ReLU() # metodo nuovo
self.linear2 = nn.Linear(hidden_size, num_classes) # altro metodo che prende 2 arg
def forward(self, x): # devo passare l'input: x
out = self.linear1(x)
out = self.relu(out)
out = self.linear2(out)
# NON USARE softmax, e' gia' messa nella Loss che usiamo popi
return(out)
model = NeuralNet2(input_size=28*28, hidden_size=5, num_classes=3) # istanzio il modello
criterion = nn.CrossEntropyLoss() # Applica gia' la Softmax di default.
################# Classificazione binaria ############################
# num_classes = 1 # il risultato vale un numero da [0,1]
# model = NeuralNet1(input_size = 28*28, hidden_size = 5)
# critetrion = nn.BCELoss()
Activation Function
[Video] (https://www.youtube.com/watch?v=3t9lZM7SS7k&list=PLqnslRFeH2UrcDBWF5mfPGpqQDSta6VK4&index=12&ab_channel=PythonEngineer) di riferimento di Python Engineer
- ReLU rectified linear unit _/
Le funzioni di attivazione vengono applicate dopo avere fatto il prodotto scalare e si applicano a tutti i neuroni/nodi (hidden).
Nel video dice che se non mettiamo delle funzioni di attivazione si ha un gigantesco livello lineare (il disegno e’ in un certo senso sbagliato, quello al minuto 1:15). All’inizio pensavo sbagliasse, ma ripensandoci ha completamente ragione. Per esempio supponiamo che ci siano solo due variabili di ingresso (x,y) e 2 nodi nel primo hidden layer:
- $a_1x+b_1y$
- $c_1x+d_1y$
(evito i bias che tanto sono costanti). A questo punto mettiamo un secondo hidden layer con 2 nodi e ottengo:
- $a_2(a_1x+b_1y) + b_2(c_1x+d_1y)$ $\rightarrow$ $(a_2 a_1 + b_2 c_1) x+(a_2 b_1 + b_2 d_1)y $
- $c_2(a_1x+b_1y) + d_2(c_1x+d_1y)$ $\rightarrow$ $(c_2 a_1 + d_2 c_1) x+(c_2 b_1 + d_2 d_1)y $
Non ho mai termini quadratici o cubici in x o y. Se non ci fossero le funzioni di attivazione sarebbe proprio un modello lineare, in cui non avrebbe nemmeno senso mettere tanti nodi al primo hidden layer (e tantomeno mettere piu’ di un layer!)
Alla fine del capitolo successivo (il 13) ho provato a fare un modello senza funzioni di attivazione. I risultati sono interessanti.
In ogni caso le funzioni lineari applicate dopo ogni layer migliorano le prestazioni.
- Step function $\displaystyle f(x)= \begin{cases} 0 & \text{if } x < 0 \ 1 & \text{if } x\ge 0\end{cases}$
- Sigmoid
nn.Sigomoid$\displaystyle f(x) = \frac{1}{1+e^{-x}}$ - Tanh
nn.TanH$\displaystyle f(x) = \frac{2}{1+e^{-2x}} -1$ - ReLU
nn.ReLU$\displaystyle f(x)= \begin{cases} 0 & \text{if } x < 0 \ x & \text{if } x\ge 0\end{cases}$ - Leacky ReLU
nn.LeakyReLU$\displaystyle f(x)= \begin{cases} ax & \text{if } x < 0 \ x & \text{if } x\ge 0\end{cases}$ con $a < 1$ - Softmax
nn.Softmax$\displaystyle S(y_i) = \frac{e^y_i}{ \sum_i e^{y_i}}$
Sono disponibili anche come funzioni di Torch, ma in questo caso i nomi sono tutti in minuscolo:
nn.ReLU()$\leftrightarrow$torch.relu()nn.Sigmoid()$\leftrightarrow$torch.sigmoid()nn.Softmax()$\leftrightarrow$torch.softmax()nn.TanH()$\leftrightarrow$torch.tanh()
In alcuni casi le funzioni non sono disponibili da Torch, ma si deve passare da torch.nn.functional:
- F.relu()
- F.leaky_relu()
import torch
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
# opzione 1: creare un modulo nn
class NeuralNet1(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(NeuralNet1, self).__init__() # questo serve per ereditare il costruttore?
self.linear1 = nn.Linear(input_size, hidden_size) #
self.relu = nn.ReLU() # metodo nuovo
self.linear2 = nn.Linear(hidden_size, 1) # altro metodo che prende 2 arg
self.sigmoid = nn.Sigmoid()
def forward(self, x): # devo passare l'input: x
out = self.linear1(x)
out = self.relu(out)
out = self.linear2(out)
out = self.sigmoid(out)
return out
# opzione 2: usare le funzioni di attivazione di Torch
class NeuralNet2(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(NeuralNet2, self).__init__() # questo serve per ereditare il costruttore?
self.linear1 = nn.Linear(input_size, hidden_size) #
self.linear2 = nn.Linear(hidden_size, 1) # altro metodo che prende 2 arg
def forward(self, x): # devo passare l'input: x
out = torch.relu(self.linear1(x)) # ho usato le funzioni di torch
out = torch.sigmoid(self.linear2(out))
return out
Comments