
Pytorch 5 Convolutional Neural Network
Posted on 15/10/2021, in Italiano. Reading time: 43 minsIndice Globale degli argomenti tra i vari post:
1.1. Indice degli argomenti.
1.1. Introduzione e fonti.
1.1. Lingo - Gergo utilizzato.
1.2. Tensori in Pytorch.
2.1. Chainrule e Autograd.
2.2. Backpropagation.
3.1. Loss e optimizer.
3.2. Modelli di Pytorch.
3.3. Dataset e Dataloader.
3.4. Dataset Transforms.
3.5. Softmax e Cross-Entropy Loss.
3.6. Activation Function.
4.1. Feed Forward Neural Network.
5.1. Convolutional Neural Network.
5.2. Transfer Learning.
5.3. Tensorboard.
6.1. I/O Saving and Loading Models.
7.1. Recurrent Neural Networks.
7.2. RNN, GRU e LSTM.
8.1. Pytorch Lightning.
8.2. LR Scheduler.
9.1. Autoencoder.
Convolutional Neural Network
Video-Lezione del MIT sulle CNN (Inglese).
Una video-lezione estesa sugli stessi argomenti e dagli stessi autori qui
Materiale della lezione: http://introtodeeplearning.com
qui vediamo degli esempi specifici riguardo le reti convoluzionali.
- L’esempio e’ basato sul dataset CIFAR-10.
- 10 classi, 6000 immagini per classe.
- ogni immagine sono 32 x 32
- ogni immagine ha 3 canali
- 50 000 immagini di training e 10 000 immagini di test
- Il dataset sembra gia’ essere diviso in batches
Problema ho implementato fino a criterion ma ho un errore quando istanzio il modello (prima di averlo riempito…
forse e’ per quello). 'ConvNet' object has no attribute '_modules'
-Domanda: Non mi e’ chiaro come vengano gestiti i casi di 3 canali di colore. Come faccio ad associarli a una singola immagine? -Risposta. Posso pensare i 3 canli come un’immagine una sopra l’altra. Le convoluzioni applicano in modo indipendente ai 3 canali, ma alla fine quando faccio un flatten li metto tutti in un unico tensore 1D (forse)
Regola del numero di punti restanti in funzione di una convoluzione/ pooling,
- w = larghezza dell’
immagine. - F = larghezza del
filtro - P = larghezza del
padding - S = stride
Risultato (minuto 14:00 del tutorial 14):
\(\frac{W-F+2P}{S}+1\)
(in questo caso P =0 dato che non ho padding, e S=1 in quanto il kernel si muove di un quadretto per volta)
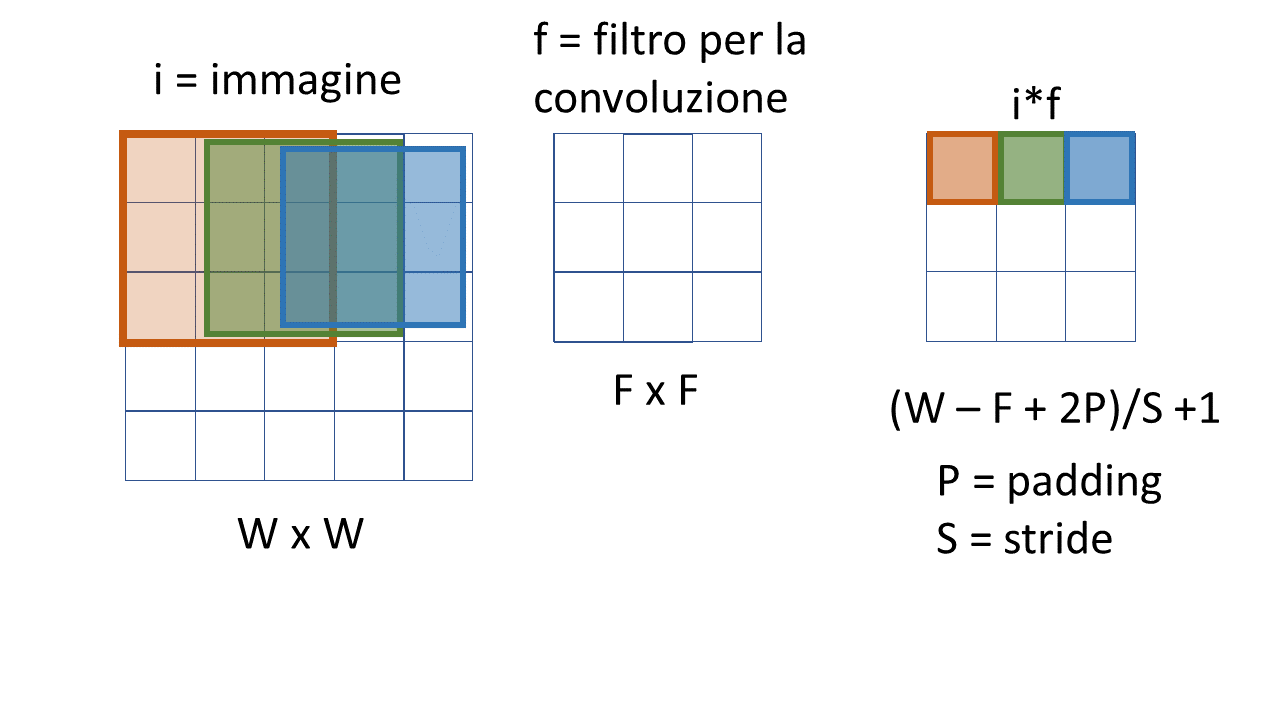 (nota che i quadrati colorati successivi sono un po’ piu’ piccoli per evitare sovrapposizioni ma riguardano
tutti i punti delle celle che toccano)
Ora viene implementata una rete neurale con la seguente (immagine da internet, non penso sia di Loeber) struttura:
(nota che i quadrati colorati successivi sono un po’ piu’ piccoli per evitare sovrapposizioni ma riguardano
tutti i punti delle celle che toccano)
Ora viene implementata una rete neurale con la seguente (immagine da internet, non penso sia di Loeber) struttura:
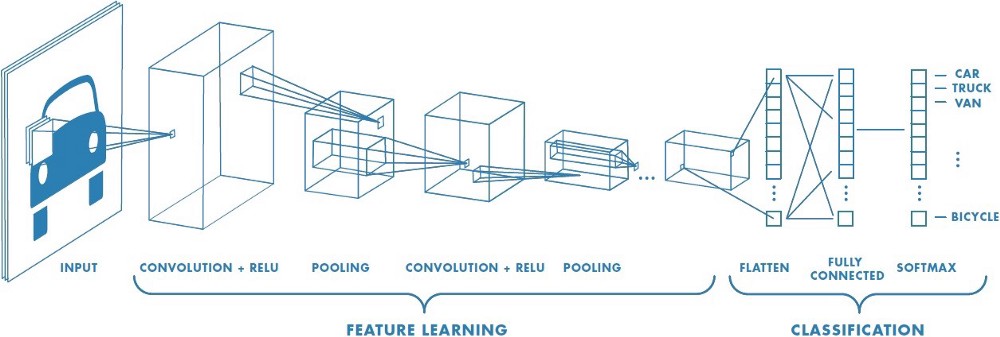
- conv + relu
- pooling
- conv + relu
- pooling
- fully connected
- fully connected
- fully connected
Come misurare le dimensioni dei tensori in uscita
Quando si hanno delle convoluzioni o dei pooling, la dimensione dei tensori in uscita non e’ facilissima da calcolare al volo, fortunatamente esiste una formula semplice.
- In torch le convoluzioni
nn.Conv2d(3,6,5)hanno 3 parametri:
- il primo parametro e’ il numero di canali in ingresso (per esempio 3, associati a r g b).
- il secondo parametro e’ il numero di canali in USCITA, nell’esempio sopra 6. Cosa significa? significa che ho preso 6 kernel differenti (riempiti con valori random) e li ho applicati tutti e 6 (ipotesi mia)!
-
il terzo parametro e’ la dimensione del kernel
- ci sono i canali (in entrata di solito sono i colori, in uscita non hanno questo significato, in quanto possono cambiare.
- I max pooling hanno 2 parametri, per esempio:
nn.MaxPool2d(2,2):- la dimensione del kernel
- lo stride
Riassumendo si usa la formula (w - f +2p )/s +1 sia per convoluzione che per pooling:
- prima convoluzione (kernel 5 x 5) passo da 3 canali 32 x 32 a : (32-5-0)/1+1 = 28 x 28 ( 6 canali ,scelto da me)
- primo pooling (kernel 2 x 2) con stride 2 passo da 6 canali 28 x 28 -> (28-2-0)/2 + 1 = 14 x 14 ( 6 canali, non modificabile)
- seconda convoluzione (kernel 5 x5) passo da 6 canali 14 x 14 a -> (14 - 5 -0)/1+1 = 10 x 10 (16 canali, scelto da me)
- secondo pooling (kernel 2 x 2) passp da 16 canali 10 x 10 a -> (10-2 -0)/2 +1 = 5 x 5 (16 canali non modificabile)
Quindi quando faccio un flatten alla fine ottengo: 5 x 5 x 16 esatto come nel video!
In grassetto metto i valori che scelgo io (per esempio i canali di ouput con la convolione)
| operazione | canali input | canali output | kernel | Stride | figura input | figura output |
|---|---|---|---|---|---|---|
| I convoluzione | 3 | 6 | 5 x 5 | 1 | 32 x 32 | (32-5-0)/1+1 =28 |
| I max pooling | 6 | 6 | 2 x 2 | 2 | 28 x 28 | (28-2-0)/2+1 =14 |
| II convoluzione | 6 | 16 | 5 x 5 | 1 | 14 x 14 | (14-5-0)/1+1 =10 |
| II max pooling | 16 | 16 | 2 x 2 | 2 | 10 x 10 | (10-2-0)/2+1 = 5 |
Osservazione
- alla funzione di convoluzione vengono passati come argomenti solo: i
canali di ingresso,canali di uscitae ladimensione del kernel, per esempio:nn.Conv2d(3,6,5) Nonsi passa la dimensione delle figure, viene presa in automatico!- alla funzione di max pool invece si passano solo: la
dimensione del kerneledimensione della stride:nn.MaxPool2d(2,2)
Problemi:
- ho provato ha mettere dei valori custom degli strati finali fully connected, non mi prende hidden_size2, ma se metto un valore preciso lo prende… perche? Il motivo era che avevo messo queste quantita’ dentro la classe indentando. Se le metto fuori, vengono prese come variabili globali!
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
%matplotlib inline
# device config
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Hyper parametri
input_size = 32*32 # =1024 sono le dimensioni delle immagini
num_classes = 10 # devo classificare immagini di numeri
num_epochs = 6 # quanti giri completi vengono fatti
batch_size = 4 # questo no so come sia stato scelto
learning_rate = 0.001 # piccolo
hidden_size1 = 220 # scelto da me
hidden_size2 = 184 # scelto da me
transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize( (0.5,0.5,0.5), (0.5,0.5,0.5) ) ] )
train_dataset = torchvision.datasets.CIFAR10(root= './data/', train= True,
transform =transform, # uso le trasformazioni indicate sopra
download = True)
test_dataset = torchvision.datasets.CIFAR10(root= './data/', train= False,
transform =transform,
download = False) # ho gia' scaricato tutto con il train_datast
train_loader = torch.utils.data.DataLoader(dataset= train_dataset, batch_size = batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader (dataset= test_dataset, batch_size = batch_size, shuffle=False)
# Pytorch lavora con numeri, qui assegno i nomi corrispondenti
# 0 1 2 3 4 5 6 7 8 9
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
def imshow(img):
img = img /2 + 0.5 # "denormalizza" forse per avere dei colori migliori
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1,2,0)))
######### MODELLO ###############
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5) # input channel size, output channel size, Kernel size 5 (5x5)
self.pool = nn.MaxPool2d(2,2) # kernel size, stride (e' un quadrato 4x4 diviso in 4 parti 2x2)
self.conv2 = nn.Conv2d(6, 16, 5) # input channel size = out di prima = 6, scelgo l'out= 16 e kernel size 5 (5x5)
self.fc1 = nn.Linear(16*5*5, hidden_size1) # fully connected (spiegato dopo) ingresso, e 120 in uscita
self.fc2 = nn.Linear(hidden_size1, hidden_size2) # in ingresso prende l'uscita del precedente e in output un tensor 1D con 84 ingressi
self.fc3 = nn.Linear(hidden_size2, 10) # in uscita ho solo le 10 classi di oggetti (riga 38)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x))) # MaxPool(ReLU(convoluzione(immagine))
x = self.pool(F.relu(self.conv2(x))) # MaxPool(ReLU(convoluzione( ))
x = x.view(-1, 16*5*5) # metto l'immagine processata in un vettore 1D
x = F.relu(self.fc1(x)) # ReLU(fc())
x = F.relu(self.fc2(x)) # ReLU(fc())
x = self.fc3(x) # qui non faccio la ReLU, perche' poi nella cross entropy c'e' softmax
return x
model = ConvNet().to(device) # metto sul device
criterion = nn.CrossEntropyLoss() # serve per fare la LOSS, include la softmax per l'ultimo strato
optimizer = torch.optim.SGD(model.parameters(), lr = learning_rate)
n_total_steps = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
# forma [4, 3, 32, 32] -> [4, 3, 1024] 4 immagini, 3 canali di colore, 32 x 32
# input layer: 3 canali di input, 6 canali di uscita, 5 kernel size
images = images.to(device)
labels = labels.to(device)
# forward
outputs = model(images)
loss = criterion(outputs, labels)
# backward e ottimizzazione dei pesi
optimizer.zero_grad()
loss.backward() # chain rule
optimizer.step() # step di ottimizzazione dato il learning rate
if (i+1) % 1000 ==0:
print(f'epoch {epoch+1} / {num_epochs}, step {i+1}/{n_total_steps}, loss= {loss.item():.4f}')
print("Training Terminato")
# qui faccio la fase di testing:
with torch.no_grad():
n_correct = 0
n_samples = 0
n_class_correct = [0 for i in range(10)] # e' una lista uso una list-comprehension
n_class_samples = [0 for i in range(10)] # non chiaro cosa sia questo
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
n_samples += labels.size(0) # non serve una quadra?
n_correct += (predicted == labels).sum().item() # questa da capire bene
for i in range (batch_size):
label = labels[i] # gira nel batch, label della singola immagine
pred = predicted[i] # guarda la riga 90
if (label == pred):
n_class_correct[label] += 1 # fa un istogramma
n_class_samples [label] +=1 # ne ho trovsata una un piu' della classe label
acc = 100.0 * n_correct / n_samples # percentuale di corrette sul totale dei sample
print(f'Accuracy = {acc}:.4f')
for i in range(10):
acc = 100.0 *n_class_correct[i]/ n_class_samples[i] # accuracy della singola classe
print(f'Accuracy della classe {classes[i]}: {acc} %' )
Files already downloaded and verified
epoch 1 / 6, step 1000/12500, loss= 2.3000
epoch 1 / 6, step 2000/12500, loss= 2.3080
epoch 1 / 6, step 3000/12500, loss= 2.3117
epoch 1 / 6, step 4000/12500, loss= 2.2834
epoch 1 / 6, step 5000/12500, loss= 2.2788
epoch 1 / 6, step 6000/12500, loss= 2.2987
epoch 1 / 6, step 7000/12500, loss= 2.2965
epoch 1 / 6, step 8000/12500, loss= 2.3122
epoch 1 / 6, step 9000/12500, loss= 2.1770
epoch 1 / 6, step 10000/12500, loss= 2.2453
epoch 1 / 6, step 11000/12500, loss= 1.9151
epoch 1 / 6, step 12000/12500, loss= 2.1131
epoch 2 / 6, step 1000/12500, loss= 2.2575
epoch 2 / 6, step 2000/12500, loss= 1.6527
epoch 2 / 6, step 3000/12500, loss= 1.3318
epoch 2 / 6, step 4000/12500, loss= 1.4340
epoch 2 / 6, step 5000/12500, loss= 2.3746
epoch 2 / 6, step 6000/12500, loss= 1.9364
epoch 2 / 6, step 7000/12500, loss= 2.1739
epoch 2 / 6, step 8000/12500, loss= 2.1157
epoch 2 / 6, step 9000/12500, loss= 1.5521
epoch 2 / 6, step 10000/12500, loss= 1.7367
epoch 2 / 6, step 11000/12500, loss= 1.6836
epoch 2 / 6, step 12000/12500, loss= 1.8475
epoch 3 / 6, step 1000/12500, loss= 1.7431
epoch 3 / 6, step 2000/12500, loss= 2.2294
epoch 3 / 6, step 3000/12500, loss= 2.5908
epoch 3 / 6, step 4000/12500, loss= 1.4687
epoch 3 / 6, step 5000/12500, loss= 1.6939
epoch 3 / 6, step 6000/12500, loss= 1.4162
epoch 3 / 6, step 7000/12500, loss= 1.5874
epoch 3 / 6, step 8000/12500, loss= 1.5107
epoch 3 / 6, step 9000/12500, loss= 1.7396
epoch 3 / 6, step 10000/12500, loss= 1.6814
epoch 3 / 6, step 11000/12500, loss= 2.7111
epoch 3 / 6, step 12000/12500, loss= 1.9274
epoch 4 / 6, step 1000/12500, loss= 1.4081
epoch 4 / 6, step 2000/12500, loss= 1.0557
epoch 4 / 6, step 3000/12500, loss= 1.9581
epoch 4 / 6, step 4000/12500, loss= 1.2325
epoch 4 / 6, step 5000/12500, loss= 2.0073
epoch 4 / 6, step 6000/12500, loss= 1.1686
epoch 4 / 6, step 7000/12500, loss= 2.1211
epoch 4 / 6, step 8000/12500, loss= 1.8252
epoch 4 / 6, step 9000/12500, loss= 1.3711
epoch 4 / 6, step 10000/12500, loss= 0.7326
epoch 4 / 6, step 11000/12500, loss= 1.5150
epoch 4 / 6, step 12000/12500, loss= 1.2301
epoch 5 / 6, step 1000/12500, loss= 1.7059
epoch 5 / 6, step 2000/12500, loss= 1.4075
epoch 5 / 6, step 3000/12500, loss= 1.5126
epoch 5 / 6, step 4000/12500, loss= 1.4504
epoch 5 / 6, step 5000/12500, loss= 1.7903
epoch 5 / 6, step 6000/12500, loss= 1.4010
epoch 5 / 6, step 7000/12500, loss= 1.5074
epoch 5 / 6, step 8000/12500, loss= 1.0711
epoch 5 / 6, step 9000/12500, loss= 0.9101
epoch 5 / 6, step 10000/12500, loss= 1.4603
epoch 5 / 6, step 11000/12500, loss= 1.5229
epoch 5 / 6, step 12000/12500, loss= 1.2879
epoch 6 / 6, step 1000/12500, loss= 0.9052
epoch 6 / 6, step 2000/12500, loss= 1.2526
epoch 6 / 6, step 3000/12500, loss= 1.0965
epoch 6 / 6, step 4000/12500, loss= 1.1149
epoch 6 / 6, step 5000/12500, loss= 1.2192
epoch 6 / 6, step 6000/12500, loss= 1.1820
epoch 6 / 6, step 7000/12500, loss= 1.4098
epoch 6 / 6, step 8000/12500, loss= 1.8098
epoch 6 / 6, step 9000/12500, loss= 1.0243
epoch 6 / 6, step 10000/12500, loss= 1.3008
epoch 6 / 6, step 11000/12500, loss= 0.9658
epoch 6 / 6, step 12000/12500, loss= 1.0129
Training Terminato
Accuracy = 52.13:.4f
Accuracy della classe plane: 49.5 %
Accuracy della classe car: 71.5 %
Accuracy della classe bird: 49.9 %
Accuracy della classe cat: 33.7 %
Accuracy della classe deer: 29.7 %
Accuracy della classe dog: 32.7 %
Accuracy della classe frog: 78.4 %
Accuracy della classe horse: 50.6 %
Accuracy della classe ship: 69.7 %
Accuracy della classe truck: 55.6 %
Transfer Learning
In questo paragrafro viene spiegato come usare parzialmente dei modelli gia’ “trainati” per fare dei nuovi compiti simili. Curiosamente questo sembra funzionare molto bene. Dico curiosamente perche’ non e’ chiaro il motivo per cui una rete neurale che ha un training su degli oggetti possa andare bene anche su degli oggetti differenti. A meno che, in qualche modo, si siano imparate delle caratteristiche generali dal primo training.
Quello che e’ davvero potente e’ che modificando l’ultimo layer posso cambiare il numero di valori in uscita. Con Resnet18 ci sono 1000 classi in uscita. Cambio l’ultimo layer e me ne servono solo 2 in uscita: no problem!
- per esempio faccio il training per un modello che classifica uccelli e gatti
- con una piccola modifica gli faro’ classificare api e cani
Osservazione
- gli uccelli hanno caratteristiche in comune alle api (non mi pare scelto a caso!)
- i cani hanno caratteristiche in comune ai gatti (anche questo non mi pare a caso)
Quindi il transfer learning, intuitivamente, funziona bene quando le modifiche da fare sono piccole (e’ un pensiero mio).
Si cambia solo l’ultimo strato fully connected (rispetto al caso precedente gli ultimi 3 strati),
questo e’ infatti lo strato di classificazione. Gli strati precedenti tramite le convoluzioni e i pooling dovrebbero estrarre le caratteristiche dei vari oggetti.
- Intuitivamente mi viene da dire che gli strati convoluzionali prendono i “pezzi” (p.es le ali, le zampe, ecc, ma nella realta’ prendono dettagli molto piu’ piccoli)
- gli strati finali mettono insieme questi pezzi elementari.
- quindi mi viene da dire che dovrebbe bastare 1 strato fully connected.
- in realta’ nel video di 3blue1brown si vede che non e’ molto chiaro cosa venga preso nei vari passaggi.
In questo caso vediamo anche come caricare un modello gia’ “trainato” (devo trovare un nome migliore…ma dire con i pesi ottimizzati e’ lungo e anche modello ottimizzato non mi piace):
Resnet18NN
- basato sul Imagenet database (con piu’ di 1 000 000 immagni)
- ha 18 strati
- classifica oggetti di 1000 categorie.
Attenzione che qui fa una cosa leggemente diversa da quanto fatto finora, dove si costruisce il modello e lo si lancia da un loop.
In questo caso costruisce una funzione
Image Folder
Costruire un folder dove mettere le immagini che devono servire per train e test.
Il folder che contiene le immagini che vogliamo usare come nuovo training ha il seguente formato:
- train
- ants
- bees
- val
- ants
- bees
Quindi se la struttura e’ questa chiamando datasets.Imagefolder posso leggere e trasformare in un dataset.
Posso inoltre usare l’attributo classes.
Scheduler
- E’ una funzione che modifica il learning rate durante il training per ottimizzare la discesa dei gradienti.
Fine Tuninig
tengo tutto il modello pre-trainato ma modifico solo l’ultimo layer
Domande
per come e’ scritto il codice sembra che in varie epoche i modelli siano diversi, non ci sia un aggiornamento continuo. In pratica fa una deepcopy del miglior modello (ma io dovrei salvare, altrimenti perdo tutto e devo rifare)
Non riesco a trovare il modello!? dove lo ha caricato? Non lo ha ancora caricato!
model.train()metodo che fa il training?
Tempo
- se freezo il train tranne l’ultimo layer ci mette 1:42 s
- se re-train tutto il modello ci ha messo circa 2:14 s
(ricorda che partiva gia’ trainato)
Train() e Eval()
sono due metodi associati al modello che precedentemente non avevo usato
# prendo e modifico il codice di prima secondo quanto scritto nella lezione 14
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import lr_scheduler # nuovo non ancora caricato prima
import torchvision
#import torchvision.transforms as transforms
from torchvision import datasets, models, transforms #
import matplotlib.pyplot as plt
import time # per controllare l'orario
import os # per interagire con l'os
import copy # per fare una deep copy del modello che e' un oggetto complesso (non vogliamo shallow copy)
import sys # per bloccare (c'e' una funzione tipo stop del fortran)
%matplotlib inline
# device config
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
mean = np.array([0.485, 0.456, 0.406]) # queste non so come sono state scelte
std = np.array([0.229, 0.224, 0.225]) # idem
# Hyper parametri
input_size = 32*32 # =1024 sono le dimensioni delle immagini
num_classes = 10 # devo classificare immagini di numeri
num_epochs = 6 # quanti giri completi vengono fatti
batch_size = 4 # questo no so come sia stato scelto
learning_rate = 0.001 # piccolo
hidden_size1 = 220 # scelto da me
hidden_size2 = 184 # scelto da me
# qui faccio un dizionario che contiene le trasformazioni da applicare
data_transforms = {
'train': transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean,std)])
,
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean,std)
])
}
# import data
data_dir = 'data/hymenoptera_data' # dove ci sono le api? Imenotteri
sets = ['train', 'val'] # lista che contiene mi sa che poi non lo usa
# Questo sotto e' da pensare un momento
# e' una list comprehension (in un dictionary)
# dove in realta' ci sono 2 directory, poteva mettere il path... e forse scriveva meno.
# in ogni caso la parte che non mi e' chiarissima sono i : dopo la x
# no e' banale: e' un dictionary e la x sono le chiavi e le datasets.Image... sono i valori
# tutti ottenuti con una list comprehension finale
image_datasets= {x:datasets.ImageFolder( os.path.join(data_dir, x), data_transforms[x] )
for x in ['train', 'val'] }
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x],
batch_size = batch_size,
shuffle= True,
num_workers= 0) for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes # .classes e' un attributo
print(class_names)
#sys.exit() # per fermare qui
######### funzione che contiene il training loop ##############
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
since = time.time() # penso chen questo sia il momento d'inizio
best_model_wts = copy.deepcopy(model.state_dict()) # fa una deep copy del modello
best_acc = 0.0 #
for epoch in range(num_epochs):
print(f'Epoch {epoch}/{num_epochs-1}')
print('-'* 10) # disegna una riga orizzontale
# In ogni epoca si ha una fase di training e validation:
for phase in ['train', 'val']:
if phase== 'train':
model.train() # set model to train mode #######################
else:
model.eval() # set model to evaluation mode
running_loss = 0.0 # in qualche modo voglio vedere live se il training va bene
running_corrects =0
for inputs, labels in dataloaders[phase]: # distinguo tra le fasi train/val
inputs = inputs.to(device)
labels = labels.to(device)
################ forward pass
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs,labels)
################ backward pass
if phase == 'train':
optimizer.zero_grad() # non mi seve quando faccio l'ottimizzazione
loss.backward() # chain rule
optimizer.step() # mi muovo in funzione del gradiente
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds==labels.data)
if phase =='train':
scheduler.step() # ========================= questo aggiorna il learning_rate
epoch_loss =running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f} ')
# deep copy model
if phase =='val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict()) # questo copia il dizionario associato al miglior modello
print()
time_elapsed = time.time() -since
print(f'Training completato in {time_elapsed//60:.0f} minuti {time_elapsed%60:.0f}s ')
model.load_state_dict(best_model_wts)
return model
######### importiamo il MODELLO ###############
model = models.resnet18(pretrained=True ) # qui il modello e' importato da torchvision e lo mette nella cache
# se voglio bloccare tutti i parametri tranne quelli dell'ultimo layer basta che
# li blocco:!
for param in model.parameters():
param.requires_grad = False # non fa il gradiente!
num_ftrs = model.fc.in_features # ho preso il layer fully connected (ultimo) e queste sono le input features?
# ora creo un nuovo layer e lo assegno come ultimo layer.
# come faccio a sapere che l'ultimo layer si chiama `fc`?
model.fc = nn.Linear(num_ftrs, 2) # ho solo 2 classi in uscita. DI DEFAULT ha requires_grad = True
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001 ) # occhio che lui aveva importato in modo diverso e chiama solo optim.SGD
############ SCHEDULER che fa una update del lr #######
step_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1) # ogni 7 epoch lr =lr*gamma (diventa 1/10)
#for epoch in range(100):
# train() # optimizer.step()
# evaluate()
# scheduler.Step()
model = train_model(model, criterion, optimizer, step_lr_scheduler, num_epochs=20)
# qui alla fine ho trovato il modello ottimale, e potrei salvarlo volendo.
['ants', 'bees']
Epoch 0/19
----------
train Loss: 0.6456 Acc: 0.6230
val Loss: 0.5187 Acc: 0.8039
Epoch 1/19
----------
train Loss: 0.5606 Acc: 0.7049
val Loss: 0.4390 Acc: 0.8627
Epoch 2/19
----------
train Loss: 0.5181 Acc: 0.7623
val Loss: 0.4065 Acc: 0.8301
Epoch 3/19
----------
train Loss: 0.4886 Acc: 0.7910
val Loss: 0.3304 Acc: 0.8954
Epoch 4/19
----------
train Loss: 0.4584 Acc: 0.8197
val Loss: 0.3134 Acc: 0.8954
Epoch 5/19
----------
train Loss: 0.4822 Acc: 0.7623
val Loss: 0.2991 Acc: 0.9085
Epoch 6/19
----------
train Loss: 0.4221 Acc: 0.8115
val Loss: 0.2734 Acc: 0.9216
Epoch 7/19
----------
train Loss: 0.4034 Acc: 0.8156
val Loss: 0.2741 Acc: 0.9216
Epoch 8/19
----------
train Loss: 0.3629 Acc: 0.8852
val Loss: 0.2734 Acc: 0.9216
Epoch 9/19
----------
train Loss: 0.4139 Acc: 0.8197
val Loss: 0.2570 Acc: 0.9216
Epoch 10/19
----------
train Loss: 0.4058 Acc: 0.8402
val Loss: 0.2794 Acc: 0.9085
Epoch 11/19
----------
train Loss: 0.4000 Acc: 0.8238
val Loss: 0.2611 Acc: 0.9346
Epoch 12/19
----------
train Loss: 0.4265 Acc: 0.8156
val Loss: 0.2510 Acc: 0.9346
Epoch 13/19
----------
train Loss: 0.3911 Acc: 0.8648
val Loss: 0.2729 Acc: 0.9085
Epoch 14/19
----------
train Loss: 0.4748 Acc: 0.7787
val Loss: 0.2668 Acc: 0.9216
Epoch 15/19
----------
train Loss: 0.3790 Acc: 0.8443
val Loss: 0.2865 Acc: 0.9020
Epoch 16/19
----------
train Loss: 0.3815 Acc: 0.8730
val Loss: 0.2611 Acc: 0.9412
Epoch 17/19
----------
train Loss: 0.3946 Acc: 0.8197
val Loss: 0.2722 Acc: 0.9020
Epoch 18/19
----------
train Loss: 0.4166 Acc: 0.8525
val Loss: 0.2828 Acc: 0.9085
Epoch 19/19
----------
train Loss: 0.3790 Acc: 0.8484
val Loss: 0.2649 Acc: 0.9216
Training completato in 1 minuti 42s
Tensorboard
https://pytorch.org/docs/stable/tensorboard.html
installazione, io ho usato conda: conda install -c conda-forge/label/cf202003 tensorboard
Tensorboard e’ un metodo per visualizzare tramite delle dashboard visibili da browser:
- il grafo computazionale
- l’evoluzione dei parametri (Loss, accuracy, ecc…)
- nota che e’ sviluppato per Tensorflow (ma funge anche con Pytorch)
- visualizzare istogrammi dei pesi e dei bias
- visualizzare immagini, testi, audio (eh si lavora anche con quelli)
- fare un profiling dei programmi di TensorFlow
Project embeddings in lower dimensional spaces?????
Viene usato il codice del tutorial numero 13 (il riconoscimento delle immagini dei numeri da 0 a 9). Da quel codice ho tolto quasi tutti i commenti in modo che i commenti rimanenti siano solo per l’utilizzo di tensorboard
-
Quando si lancia Tensorboard bisogna specificare il path dove verranno salvati i logfile. Di default vengono messi nella directory chiamata
run(suppongo che sia una sottodir dell’installazione di Tensorboard -
per fare partire Tensorboad (dalla dir dove si e’ lanciato il Python):
tensorboard --logdir=runs
a questo punto si apre un browser alla pagina:
http://localhost:6006
(CTRL+C = quit)
- La prima cosa che si fa e’ essenzialmente istanziare un
writer:writer=SummaryWriter('runs/mnist')(riga 12). Il writer in pratica scrive dei valori in formato JSON (controllare) con specifiche che tensorboard va a leggere nella dir runs e, note le chiavi le mette nella dashboard.
In pratica a quanto capisco, il writer scrive i dati in un formato particolare che viene poi letto da tensorboard e mandato nella dashboard al localhost:6006. Questo e’ il motivo per cui l’oggetto fondamentale e’ un writer che ha dei vari metodi in grado di scrivere le informazioni dei vari oggetti in modo che Tensorboard le interpreti correttamente.
I Esempio di utilizzo: visualizzo i dati nel browser, consiste di 3 passi (piu’ l’istanza del writer appena fatta):
- Costruisco una griglia di immagini
img_grid = torchvision.utils.make_grid(example_data)(usando le utility di torchvision) - Do in pasto la griglia al writer, tramite il metodo add_image:
writer.add_image('Immagini di Mnist', img_grid), il primo argomento una label per la image grid, il secondo e’ la griglia stessa - uso il metodo
writer.close()per assicurarmi che tutti i dati siano mandati
II Esempio di utilizzo: visualizzo il grafo computazionale. Consiste di 2 passi.
- uso il metodo
writer.add_graph(model, examples_data.reshape(-1,28*28).to(device)),quindi il primo argomento e’ il modello e il secondo sono ancora gli esempio (che ho flattenato). Attento, dato che sto mettendo tutto sul device, devo farlo anche per quanto riguarda examples_data, nel video non viene fatto! (questo perche’ il notebook usato non ha una scheda grafica dedicata e quindi sono comunque tutti sull’host. - chiudo il writer per assicurarmi che tutti i dati vengano passati:
writer.close()
Nota che dopo avere scritto l’esempio II, appare una seconda scelta in tensorboard (in alto), chiamata graph. Si vede quindi il grafo computazionale che viene visualizzato. Con dei doppi click si aprono nel dettaglio i grafi!
III Esempio di utilizzo: mando la loss e la accuracy durante l’esecuzione. Consiste di 2 passi. Vogliamo la loss media durante il training, quindi aggiungo delle variabili al mdoello.
- uso un nuovo metodo:
writer.add_scalar('Training loss', running_loss/100, epoch* n_total_steps + i)Nota che ho definito prima delle nuove quantita’ da mandare al writer tramite add_scalar
Attento se continuo a fare girare la rete neurale nel notebook, i dati in Tensorboard si accumulano a quelli dei run precedenti. Devo trovare un modo per azzerare i dati.
Soluzione:
devi rinominare la dir dove vengono salvati i dati per ogni run diverso. In questo modo si avranno delle righe di colore diverso per ogni run. Altrimenti provo ad andare a cancellare il contenuto della dir runs/mnist (occhio che e’ una cartella che viene creata nella stessa dir di dove gira il python!) (magari esiste un metodo migliore devo investigare). Ho cancellato tutto ma non funge… ok funge, li teneva in memoria! ho riavviato tensorboard ed e’ sparito tutto. La cosa curiosa e’ che aprendo gli eventi sembrano vuoti… Solo il primo contiene molti valori, il resto sono gli incrementi sul primo direi.
Attento quando ci sono degli scalari (dei grafici) di default Tensorboard aggiunge una linea di smoothing (e’ nella modale(?) subito a sinistra).
IV Eempio di utilizzo: aggiungere una precision e recall curve (riguarda le note sulla confusoin matrix per le definizioni esatte). Esiste un metodo apposta per aggiungere la precision. Guarda il link: pytorch.org/docs/stable/tensorboard.html
import numpy as np
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
%matplotlib inline
from torch.utils.tensorboard import SummaryWriter ############## TENSORBOARD
import sys
import torch.nn.functional as F
##### costruisco un writer ####################
writer =SummaryWriter('runs/mnist') # come argomento serve la dir dove vanno salvati i file
##### fine writer ########################
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
input_size = 28*28
hidden_size = 100
num_classes = 10
num_epochs = 2
batch_size = 100
learning_rate = 0.001
train_dataset = torchvision.datasets.MNIST(root= './data/', train= True , transform =transforms.ToTensor(), download = True)
test_dataset = torchvision.datasets.MNIST(root= './data/', train= False, transform =transforms.ToTensor(), download = False) #
train_loader = torch.utils.data.DataLoader(dataset= train_dataset, batch_size = batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader (dataset= test_dataset, batch_size = batch_size, shuffle=False)
examples = iter(test_loader)
examples_data, examples_targets = examples.next()
#for i in range(6):
# plt.subplot(2,3,i+1)
# plt.imshow(example_data[i][0], cmap='gray')
img_grid = torchvision.utils.make_grid(examples_data)
writer.add_image('Immagini di Mnist' , img_grid)
writer.close() # questo assicura che tutti gli output sono flushati
#sys.exit() # per non dover fare tutto il training
############ MODELLO ####################
class NeuralNet(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(NeuralNet, self).__init__()
self.l1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.l2 = nn.Linear(hidden_size, num_classes)
def forward (self, x):
out = self.l1(x)
out = self.relu(out)
out = self.l2(out)
return out
############### ISTANZIO MODELLO, Back e Forw ########
model = NeuralNet(input_size, hidden_size, num_classes).to(device)
criterion = nn.CrossEntropyLoss() # non ha bisogno di parametri
optimizer = torch.optim.Adam(model.parameters(), lr = learning_rate)
###### Aggiungo un altro grafo alla dashboard di Tensorboard,
###### ora uso il metodo add_graph (prima ho usato add_image)
writer.add_graph(model, examples_data.reshape(-1,28*28).to(device))
writer.close()
#sys.exit()
############### TRAINING LOOP ############
n_total_steps = len(train_loader)
running_loss = 0.0 # questo e' il valore aggiornato in tempo reale
running_correct = 0 # idem
for epoch in range(num_epochs):
for i, (images,labels) in enumerate (train_loader):
images = images.reshape(-1, 28*28).to(device)
labels = labels.to(device)
outputs = model (images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
################ da mandare a TENSORBOARD ####################
running_loss += loss.item() # aggiorno il totale
_, predicted =torch.max(outputs.data, 1)
running_correct += (predicted == labels).sum().item()
################ ##################### ########################
if (i+1) % 100 ==0:
#print(f'epoch {epoch+1} / {num_epochs}, step {i+1}/{n_total_steps}, loss= {loss.item():.4f}')
############## qui aggiungo alla dashboard un nuovo oggetto TENSORBOARD ######
writer.add_scalar('Training loss', running_loss/100, epoch* n_total_steps + i)
writer.add_scalar('Accuracy', running_correct/100, epoch* n_total_steps + i)
running_loss = 0.0 # riazzero
running_correct = 0 # riazzero
writer.close()
######################################################
################ per Tensorboard ########################
labels2 = [] #occhio che aveva gia' definito labels sotto, ho messo un 2 Tensorboard
preds = []
#########################################################
############ TEST LOOP #################
with torch.no_grad():
n_correct = 0
n_samples = 0
for images, labels in test_loader:
images = images.reshape(-1, 28*28).to(device)
labels = labels.to(device)
outputs = model(images)
_, predictions = torch.max(outputs,1)
n_samples += labels.shape[0]
n_correct += (predictions == labels).sum().item()
class_predictions = [F.softmax(output, dim=0) for output in outputs] # ho bisogno di probabilita', quindi serve softmax
preds.append(class_predictions)
labels2.append(predicted) # per TENSORBOARD
preds = torch.cat ([torch.stack(batch) for batch in preds ]) # tensorboard 2D oggetto 1000, 1
labels2 = torch.cat(labels2) # Tensorboard concateno le liste in un oggetto 1D 1000
classes = range(10) # tutte le possibili classi 0-9 Tensorboard
for i in classes:
labels_i = labels2 == i # Tensorboard non chiaro cosa fa
preds_i = preds[:,i] # Tensorboard
writer.add_pr_curve(str(i), labels_i, preds_i, global_step =0) # TEnsorboard
writer.close() # chiudo il writer
acc = 100.0 * n_correct / n_samples
print(f'accuracy ={acc}')
accuracy =95.03
Comments